今天接著完成翻譯任務實作的第二階段-模型推論。
上次由於輸入特徵 X 以及原始句對並非一一對應,造成了 BLEU 分數低下的結果。
分別針對訓練資料以及測試資料建立原始句對以及其特徵 X_train 、標籤 y_train :
# Generate training data
train_dataset = np.load("data/eng-cn/train_data_io.npz")
seq_pairs_train, X_train, y_train, src_vocab_size = create_data(train_dataset)
# Generate test data
test_dataset = np.load("data/eng-cn/test_data_io.npz")
seq_pairs_test, X_test, y_test, _ = create_data(test_dataset)
我們重新在訓練資料集上評估模型:
# evaluate model on training dataset
eval_NMT(seq2seq, X_train, seq_pairs_train, reverse_tgt_vocab_dict)
列出前五句的英文原句、中文原句以及中文譯句: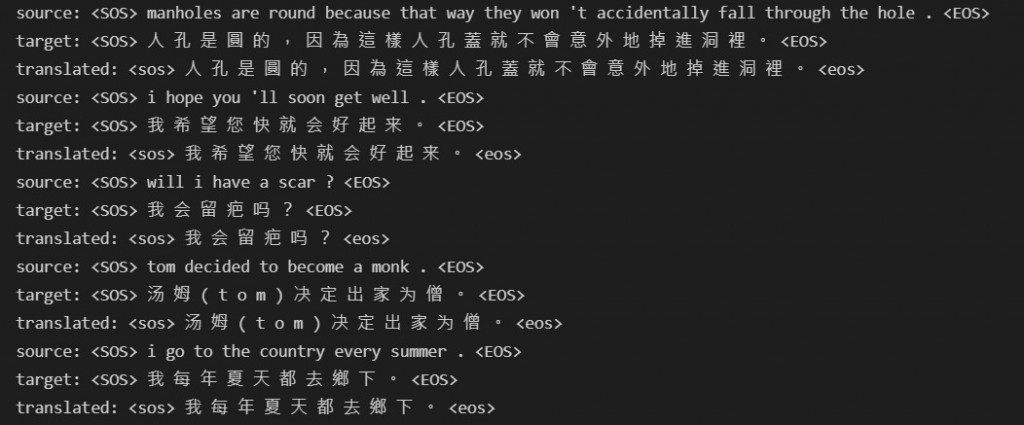
匹配各個 n-grams 而計算出的 BLEU 分數: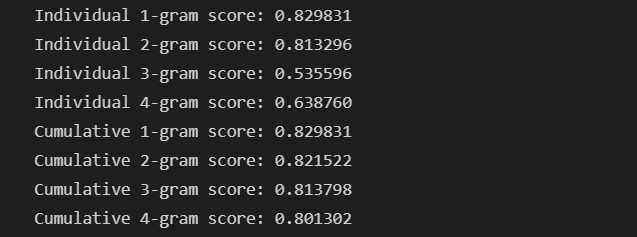
接著輪到在訓練資料集上重新評估模型:
# evaluate model on test dataset
eval_NMT(seq2seq, X_test, seq_pairs_test, reverse_tgt_vocab_dict)
列出前五句的英文原句、中文原句以及中文譯句:
匹配各個 n-grams 而計算出的 BLEU 分數: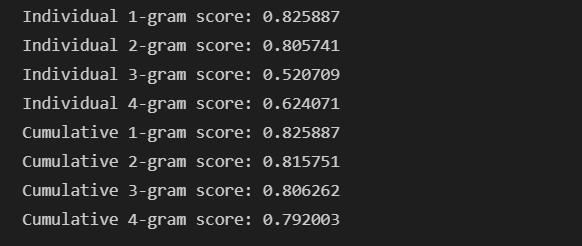
可以見到,當愈多元的 n-grams 列入準確度的計算,得到的 BLEU 就會愈低,這是必然的結果。而此模型不論是在訓練資料集或測試資料集上評估而得的 BLEU 分數皆幾乎都在 0.7 以上,準確度令人滿意。
首先將預訓練好的 seq2seq 模型載入,取出每層神經元以便沿用訓練階段收斂的參數矩陣數值:
from tensorflow.keras.models import load_model
eng_cn_seq2seq = load_model("models/eng-cn_translator_v3.h5")
layers_list = eng_cn_seq2seq.layers
layer_names = [layer.name for layer in layers_list]
weights_list = eng_cn_seq2seq.get_weights()
在訓練階段時,我們將編碼器和解碼器的輸入當作特徵一並傳入神經網絡當中。然而在實際翻譯的情境中,我們並不會預先知道目標語言的文句,也就是解碼器的輸入。因此在推論階段( inference loop )時,我們只提供來源語言文句,傳入編碼器後,再將資訊透過解碼器傳出。
習慣上我們會先提供解碼器的初始輸入為指示句首的符號<sos>,透過 token by token 的預測,更新解碼器的輸入,直到出現指示句末的符號<eos>出現,或是已經超過目標語言最大句長,則停止預測,完成整個句子的翻譯。
首先建立可獨立預測的編碼器模型:
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
layers_list = eng_cn_seq2seq.layers
layer_names = [layer.name for layer in layers_list]
weights_list = eng_cn_seq2seq.get_weights()
# Build an Encoder Model in an inference mode
enc_inputs = training_seq2seq.input[0]
enc_outputs_1, enc_h1, enc_c1 = layers_list[4].output
enc_outputs_2, enc_h2, enc_c2 = layers_list[6].output
enc_states = [enc_h1, enc_c1, enc_h2, enc_h2]
encoder_model = Model(enc_inputs, [enc_states, enc_outputs_2], name = "encoder_model")
接下來則是承接編碼器輸出資訊的解碼器模型:
# define all input tensors
dec_state_input_h1 = Input(shape = (latent_dim, ))
dec_state_input_c1 = Input(shape = (latent_dim, ))
dec_state_input_h2 = Input(shape = (latent_dim, ))
dec_state_input_c2 = Input(shape = (latent_dim, ))
src_max_seq_length = 38
enc_outputs_final = Input(shape = (src_max_seq_length, latent_dim))
dec_states_inputs = [dec_state_input_h1, dec_state_input_c1, dec_state_input_h2, dec_state_input_c2]
# Build a Decoder Model in an inference mode
embed_vec = layers_list[3](dec_inputs) # embedding layer
dec_outputs_1, dec_h1, dec_c1 = layers_list[5](embed_vec, initial_state = dec_states_inputs[:2]) # 1st LSTM layer
dec_outputs_2, dec_h2, dec_c2 = layers_list[7](dec_outputs_1, initial_state = dec_states_inputs[2:]) # 2nd LSTM layer
attention_scores = layers_list[8]([dec_outputs_2, enc_outputs_final]) # dot: attention function to get attention scores
attention_weights = layers_list[9](attention_scores)
context_vec = layers_list[10]([attention_weights, enc_outputs_final])
ht_context_vec = layers_list[11]([context_vec, dec_outputs_2])
attention_vec = layers_list[12](ht_context_vec)
logits = layers_list[13](attention_vec)
dec_outputs_final = layers_list[14](logits)
dec_states = [dec_h1, dec_c1, dec_h2, dec_c2]
# decoder_model = Model([dec_inputs] + dec_states_inputs + [enc_outputs_final], [dec_outputs_final] + dec_states, name = "decoder_model_inference_10_epochs")
decoder_model = Model([dec_inputs] + dec_states_inputs + [enc_outputs_final], [dec_outputs_final] + dec_states + [attention_weights], name = "decoder_model")
接下來則是利用編碼器承接輸入文句,傳遞給解碼器,完成整個句子的翻譯:
def decode_sequence(input_sentence):
# visualise association between tokens using the alignment matrix
attention_plot = np.zeros(shape = (tgt_max_seq_length, src_max_seq_length))
input_sentences = [input_sentence]
input_seq = encode_input_sequences(eng_tokeniser, src_max_seq_length, input_sentences)
enc_states, enc_outputs_2 = encoder_model.predict(input_seq)
# enc_states = [enc_h1, enc_c1, enc_h2, enc_c2]
dec_states = enc_states
# generate empty target sequence of length 1
tgt_seq = np.zeros(shape = (1, 1))
tgt_seq[0, 0] = tgt_vocab_dict["<sos>"]
decoded_sentence = ""
stop_cond = False
while not stop_cond:
output_tokens, new_dec_h1, new_dec_c1, new_dec_h2, new_dec_c2 = decoder_model.predict([tgt_seq] + dec_states + [enc_outputs_2])
# Sample a token: Label encode the current one-hot encoded output
# Greedy search: each time find the most likely token (last position in the sequence)
sampled_word_idx = np.argmax(output_tokens[0, -1, :])
sampled_word = reverse_tgt_vocab_dict[sampled_word_idx]
decoded_sentence += sampled_word
# Exit condition: either hit max length
# or find stop token.
if (sampled_word == "<eos>" or (len(decoded_sentence) > tgt_max_seq_length)):
stop_cond = True
# Update the target sequence (of length 1)
tgt_seq[0, 0] = sampled_word_idx
# Update decoder states
dec_states = [new_dec_h1, new_dec_c1, new_dec_h2, new_dec_c2]
return decoded_sentence
以上為推論階段的程序,內容有一些小 bug 會再修正並更新。
今天的文章更新就先到這裡,晚安!

